효율성의 마법: 1/24로 줄어든 AI 비용의 비밀(Recurrent Depth Approach)
안될 공학님의 유튜브를 보면서 관련 내용을 조금더 공부한 후 관련 내용을 정리해 보았습니다. 저는 전공자가 아니기 때문에 매우 얕은 지식을 바탕으로 제가 이해한 선에서만 정리해 보았습니다. 잘못된 부분이 있다면 알려주시면 즉시 수정하도록 하겠습니다.
기존 LLM과 새로운 모델의 근본적 차이
가. 기존 LLM의 작동 방식과 한계
기존의 대형 언어 모델(LLM)은 다음과 같은 방식으로 작동합니다:
- 리소스 사용 구조
- 거대한 파라미터(수천억 개)를 저장하기 위한 대용량 메모리 필요
- 각 레이어마다 별도의 가중치와 메모리 공간 필요
- 추론 시 모든 레이어를 한 번씩 순차적으로 통과
- Chain-of-Thought(COT) 방식의 한계
- 추론 과정을 텍스트로 출력하며 진행
- 긴 문맥 처리를 위한 추가 메모리 필요
- 토큰 생성마다 전체 모델을 다시 활용
- 확장성 문제
- 성능 향상을 위해서는 모델 크기를 키워야 함
- 더 큰 모델 = 더 많은 GPU/메모리 필요
- 운영 비용이 기하급수적으로 증가
나. 새로운 모델(Recurrent Depth)의 혁신적 접근
새롭게 제안된 모델은 완전히 다른 방식으로 리소스를 활용합니다.
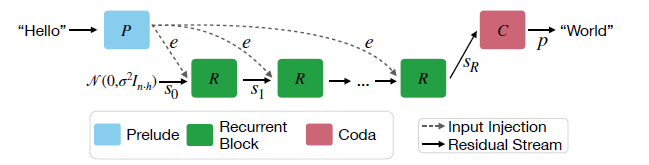
1. 메모리 사용의 혁신
a) 레이어 구조 최적화
- 기존: 수백 개의 레이어가 각각 고유한 파라미터 보유 (예: GPT-3는 96개 레이어)
- 새 방식: 소수의 레이어(예: 4개)를 여러 번 반복 사용
- 효과: 파라미터 저장 메모리 최대 24배 감소
b) KV(Key-Value) 캐시 최적화
- 기존: 각 레이어마다 별도의 KV 캐시 필요 (96개 레이어 = 96개 캐시)
- 새 방식: 소수 레이어의 캐시만 유지하고 재활용
- 효과: 캐시 메모리 사용량 대폭 감소
c) 계산 방식 효율화
- 기존: 중간 과정을 텍스트로 변환하여 저장 (Chain-of-Thought)
- 새 방식: 내부 벡터 공간에서 수치로만 계산
- 효과: 텍스트 생성과 저장에 필요한 추가 메모리 절약
2. 실제 메모리 사용 비교
- 예시
[기존 LLM]
- 96개 레이어 × 100MB = 9,600MB
- 96개 KV 캐시 × 50MB = 4,800MB
총 필요 메모리: 14,400MB
[새로운 모델]
- 4개 레이어 × 100MB = 400MB
- 4개 KV 캐시 × 50MB = 200MB
총 필요 메모리: 600MB
- 유연한 확장성
- 동일한 모델로 난이도에 따라 연산량 조절 가능
- 하드웨어 제약에 따라 반복 횟수 조정 가능
- 더 정확한 결과가 필요할 때 추가 연산 수행
이 혁신이 가져올 구체적 변화
가. 기술적 측면의 혁신
- 컴퓨팅 리소스 활용의 변화
- 기존: 1000B 파라미터 모델 = 1000B 메모리 필요
- 새로운 방식: 3.5B 파라미터로 50B 수준 성능 달성
- 실제 사례: GSM8k 수학 문제에서 반복 횟수 증가에 따라 정확도 42% 달성
- 비용 구조의 혁신
- 기존: GPU 메모리 비용이 지배적
- 새로운 방식: 연산 시간 vs 메모리 사용의 균형
- 구체적 절감: 메모리 사용량 최대 90% 감소 가능
- 성능 확장성
- 문제 난이도별 최적 반복 횟수 자동 조정
- 수학/코딩 문제: 32-64회 반복
- 일반 대화: 8-16회 반복으로 충분
- 메모리 사용 최적화의 실질적 의미
- 기존 LLM의 1/24 수준의 메모리로 유사한 성능 달성
- 동일 GPU로 더 큰 규모의 작업 처리 가능
- 클라우드 비용 대폭 감소 가능
- 로컬 장치에서도 고성능 AI 구동 가능
나. 산업별 구체적 영향
- 클라우드/데이터센터 산업
- 기존: 대규모 GPU 클러스터 필수
- 변화: 적은 수의 GPU로 더 효율적 운영 가능
- 영향: 데이터센터 설계/운영 방식의 근본적 변화
- 예시: 1000대 GPU 클러스터를 100대로 축소 가능
- AI 스타트업 생태계
- 기존: 대규모 초기 투자 필요
- 변화: 소규모 투자로도 고성능 서비스 가능
- 구체적 사례
- 교육 테크: 개인별 맞춤형 수학 교육 시스템
- 코드 분석: 실시간 버그 탐지/수정 서비스
- 금융 분석: 실시간 위험 평가 시스템
- 하드웨어 산업
- GPU 제조사: 제품 라인업 다변화 필요
- 메모리 제조사: HBM 수요 변화 대응
- 새로운 기회: 특화된 AI 가속기 시장
다. 서비스 혁신 사례
- 교육 분야
- 현재: 일괄적인 난이도의 문제 제공
- 혁신: 학생별 실시간 난이도 조정
- 구체적 구현
- 기초 개념 설명: 8회 반복
- 복잡한 문제 해결: 32회 반복
- 실시간 오답 분석: 16회 반복
- 금융 서비스
- 현재: 정해진 위험 평가 모델
- 혁신: 상황별 분석 깊이 조절
- 실제 적용
- 일반 거래: 4-8회 반복
- 대규모 위험 평가: 64회 이상 반복
- 실시간 시장 분석: 16-32회 반복
투자의 기회와 리스크에 관한 아이디어
가. 단기적 투자 아이디어
- AI 인프라 최적화 기업
- 대상: GPU 메모리 최적화 솔루션 제공 기업
- 이유: 새로운 구조에 맞는 인프라 재구성 필요
- 특화 AI 서비스 기업
- 분야: 교육, 금융, 의료, 법률 등
- 차별점: 정확도와 비용의 최적 균형
- 기회: 현재 대형 기업 독점 시장 진입하여 점유율을 확대하는 AI 기반 혁신 기업들
나. 장기적 투자 아이디어
- AI 하드웨어 혁신 기업
- 목표: 반복 연산에 최적화된 새로운 칩
- 잠재력: 기존 GPU 대체 가능성
- 시장 규모: 2030년까지 1000억 달러 예상
- 엣지 컴퓨팅 솔루션
- 특징: 로컬 장치에서 고성능 AI 구현
- 응용: IoT, 자율주행, 스마트 기기
- 성장성: 연간 40% 이상 성장 예상
다. 주의해야 할 리스크
- 기술적 리스크
- 대규모 상용화 검증 필요
- 기존 LLM과의 직접 경쟁
- 안정성/신뢰성 검증 시간 소요
- 시장 리스크
- 대형 기업의 대응 전략
- 표준화/규제 이슈
- 사용자 수용성 검증 필요
결론
지금까지 AI 산업은 '더 큰 모델 = 더 좋은 성능'이라는 단순한 공식이 지배적이었고, 이는 자연스럽게 OpenAI, Google, Microsoft 등 빅테크 기업들의 독점적 시장 지위로 이어졌습니다. 수천억 달러 규모의 인프라 투자가 필요한 현실에서, 대다수의 기업들은 시장 진입 자체를 엄두조차 내지 못했습니다.
하지만 최근 DeepSeek의 혁신을 시작으로, AI 산업은 '효율성'이라는 새로운 키워드를 중심으로 재편되고 있습니다. 이번 연구에서 제시된 '반복 연산을 통한 리소스 효율화' 역시 같은 맥락에서 주목할 만한 혁신입니다. 더 이상 거대 인프라가 없다고 해서 AI 시장에서 배제될 필요가 없게 된 것입니다.
이러한 변화는 AI 산업의 경쟁 구도를 근본적으로 바꾸고 있습니다. 이제 시장의 승자는 인프라의 규모가 아닌, 얼마나 빠르고 민첩하게 사용자들의 니즈를 파악하고 대응하는지에 따라 결정될 것입니다. 특히 주목할 점은 AI 시장의 폭발적 성장세입니다. 현재 형성된 거대한 시장에서, 기존 서비스의 불편함을 해소하는 혁신적인 솔루션으로 진입한다면 상당한 시장 점유율을 확보할 수 있는 기회가 열려있습니다.
하드웨어 측면에서는 엣지 컴퓨팅과 온디바이스 AI가 유망해 보입니다. 이번 연구에서 제시된 효율적 연산 방식은 로컬 디바이스에서도 고성능 AI 구현을 가능케 하며, 이는 프라이버시와 실시간 처리가 중요한 다양한 응용 분야를 열어줄 것입니다. 특히 자율주행, IoT, 웨어러블 기기 등에서 폭발적인 수요가 예상됩니다.
서비스 측면에서는 전문성이 요구되는 분야들이 주목됩니다. 교육 분야에서는 개인화된 학습 경험을, 법률 분야에서는 접근성 높은 법률 서비스를, 금융 분야에서는 더 정교한 위험 분석과 자산 관리를, 헬스케어 분야에서는 개인화된 건강 관리, 신약 개발에 AI 활용 솔루션을 제공하는 기업들이 유망할 것으로 보입니다. 이들 분야는 전문성의 장벽으로 인해 디지털 혁신이 더디었지만, 이제 효율적인 AI 기술을 통해 혁신의 기회가 열리고 있습니다.
결론적으로, AI 기술의 효율화는 시장 진입 장벽을 낮추고 혁신의 기회를 넓히고 있습니다. 투자자들은 단순히 큰 기업을 쫓기보다는, 효율성과 전문성을 무기로 특정 분야에서 차별화된 가치를 제공할 수 있는 기업들에 주목해야 할 것입니다. 특히 엣지 컴퓨팅 하드웨어와 전문 분야 특화 서비스는 향후 폭발적 성장이 예상되는 만큼, 이 분야의 혁신 기업들을 주의 깊게 살펴볼 필요가 있습니다.
[참고한 내용]
https://youtu.be/Cpy-__ah88c?si=a8ScDiD9QA2jsue2
https://arxiv.org/abs/2502.05171
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contras
arxiv.org